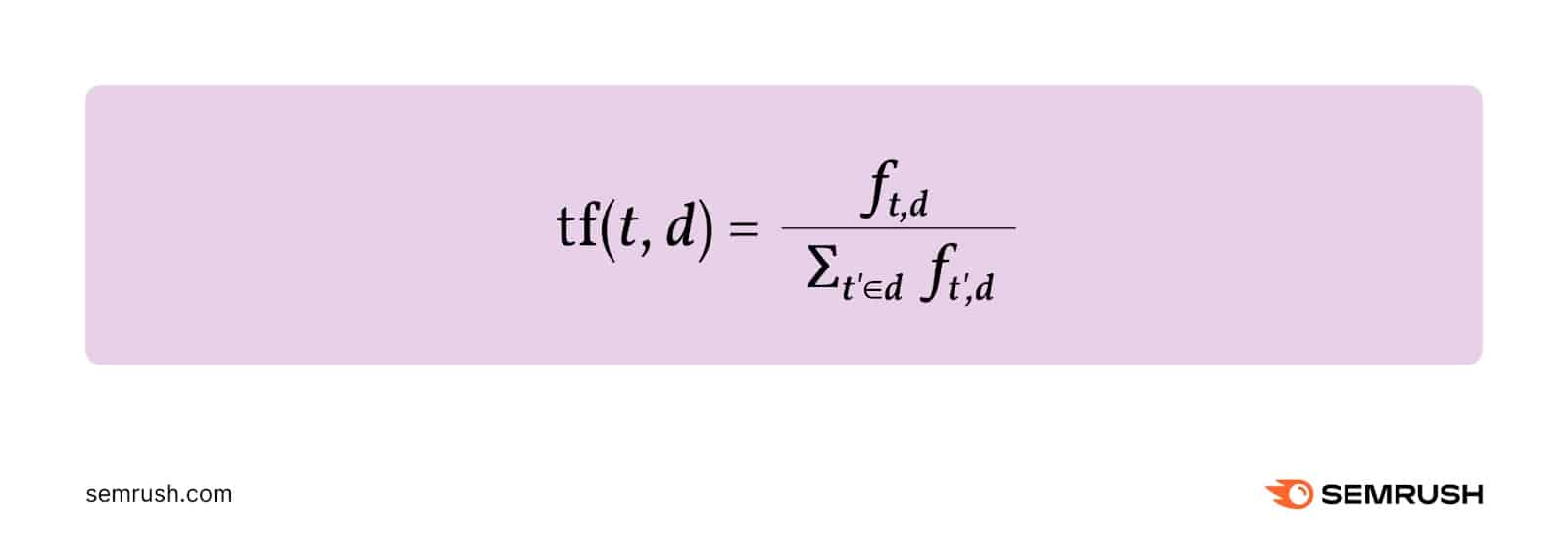
TF-IDF is a statistical methodology generally utilized in data retrieval and pure language processing.
It’s an necessary idea for understanding how search engines like google and yahoo analyze net content material and determine key phrases that may be related to search queries.
Right here’s what it’s good to learn about it.
What Is Time period Frequency-Inverse Doc Frequency (TF-IDF)?
Time period frequency-inverse doc frequency (TF-IDF) measures the significance of a phrase to a selected doc.
It’s the product of two statistics: time period frequency (TF) and inverse doc frequency (IDF).
Time period Frequency (TF)
Time period frequency (TF) will be outlined because the relative frequency of a time period (t) inside a doc (d).
It’s calculated by dividing the variety of occasions the time period happens within the doc (ft,d) by the entire variety of phrases within the doc.
Right here’s the components:
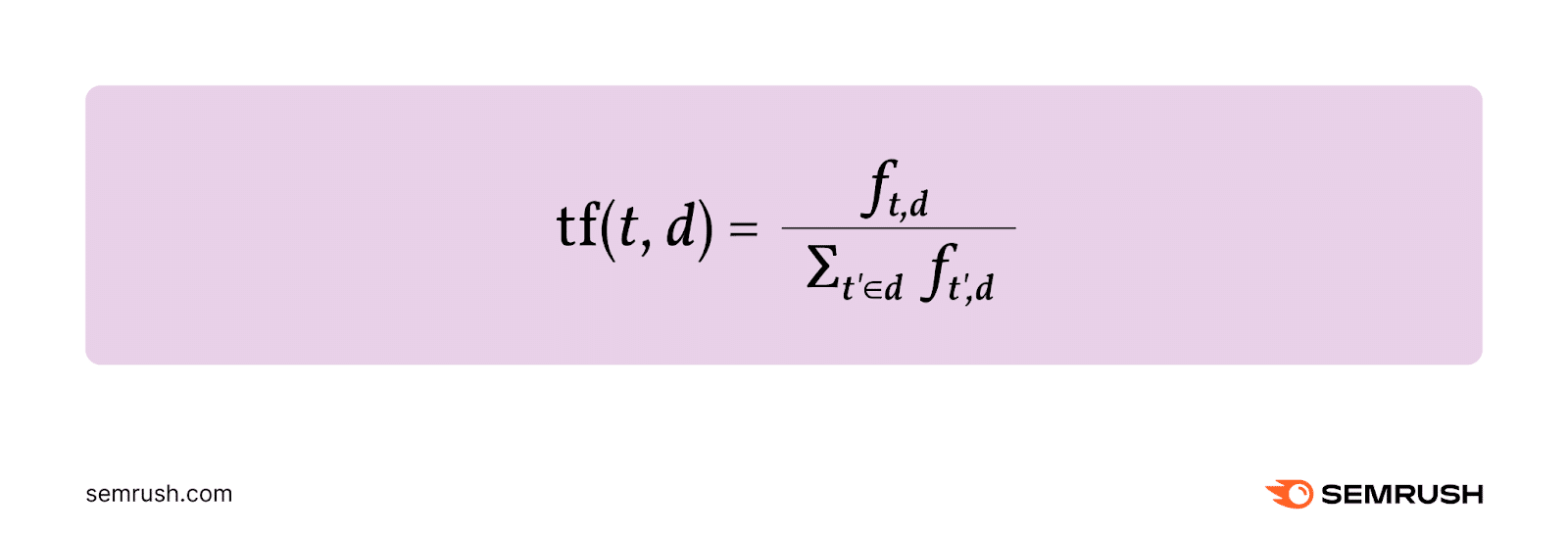

For instance, say you might have a doc containing 10,000 phrases. And a selected time period seems a complete of 25 occasions within the doc.
You’d calculate the time period frequency as follows:
TF = 25/10,000 = 0.0025
Inverse Doc Frequency (IDF)
Inverse doc frequency (IDF) measures the quantity of data a time period offers.
It’s calculated by dividing the entire variety of paperwork (N) by the variety of paperwork that include the time period. Then, taking the logarithm of that quotient.
Right here’s the components:
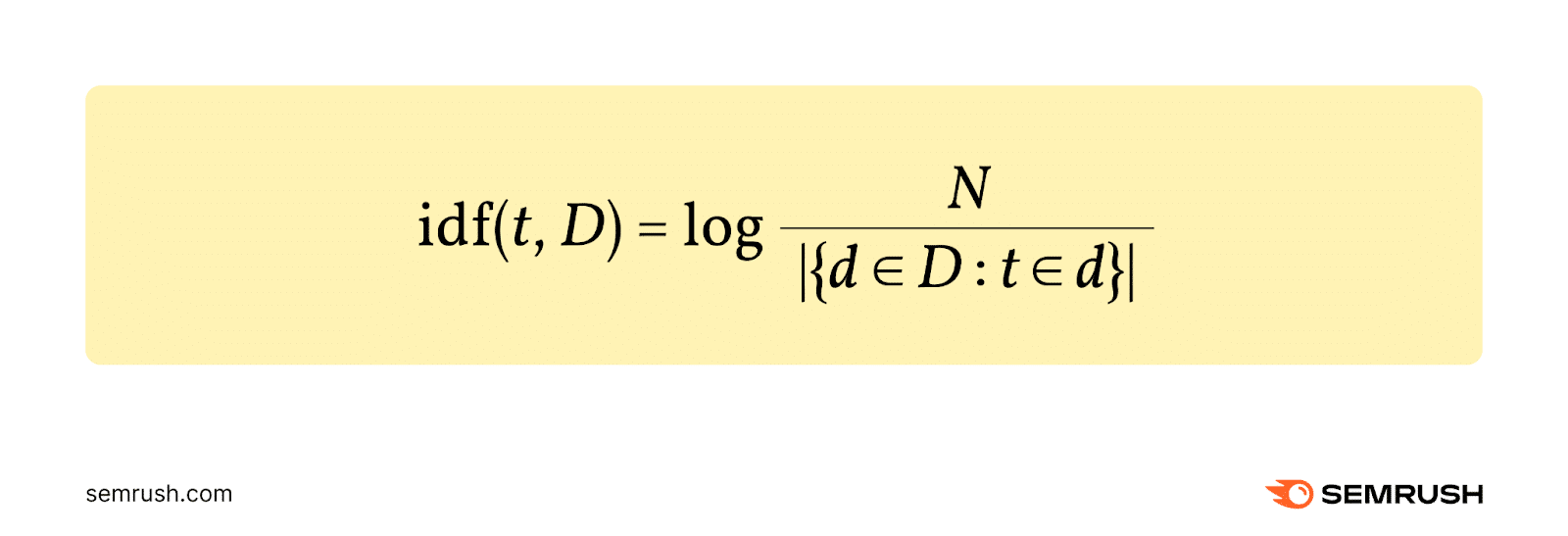
As an example you might have a group of 10,000 paperwork (N=10,000), and a time period seems in 500 of those paperwork.
Right here’s the way you’d calculate the IDF:
IDF = log 10,000/500 = 1.30
TF-IDF Components
To calculate TF-IDF, we have to multiply the values of TF and IDF:

TF-IDF = 0.00325
The ultimate rating reveals the relevance of the time period, with a better rating denoting increased relevance and a decrease rating denoting decrease relevance.
An Instance of Methods to Calculate TF-IDF
So, how does TF-IDF work in follow?
Merely inspecting the TF, IDF, and TF-IDF formulation generally is a bit overwhelming. Let’s check out an precise instance.
Let’s say that the time period “automotive” seems 25 occasions in a doc that accommodates 1,000 phrases.
We’d calculate the time period frequency (TF) as follows:
TF = 25/1,000 = 0.025
Subsequent, let’s say {that a} assortment of associated paperwork accommodates a complete of 15,000 paperwork.
If 300 paperwork out of the 15,000 include the time period “automotive,” we’d calculate the inverse doc frequency as follows:
IDF = log 15,000/300 = 1.69
Now, we will calculate the TF-IDF rating by multiplying these two numbers:
TF-IDF = TF x IDF = 0.025 x 1.69 = 0.04225
Methods to Use TF-IDF
TF-IDF has numerous purposes. It may be used as a weighting issue for:
- Data retrieval: Variations of TF-IDF are used as a weighting issue by search engines like google and yahoo to assist perceive the relevance of a web page to a consumer’s search question
- Textual content mining: TF-IDF might help quantify what a doc is about, which is a central query in textual content mining
- Consumer modeling: One other software of TF-IDF includes aiding within the creation of fashions for consumer habits and pursuits, which might then be utilized by product and content material suggestion engines
Use Semrush’s On Web page search engine optimization Checker for TF-IDF
Trying to do a little bit of TF-IDF evaluation in your personal web site? That is the place Semrush’s On Web page search engine optimization Checker might help.
You need to use it to check TF-IDF scores between your web site content material and competing pages.
Right here’s how:
Enter your area on the On Web page search engine optimization Checker web page and hit the “Get concepts” button.

The instrument will then analyze your web site. And current you with a report containing a listing of concepts for optimizing your web site for search engines like google and yahoo.
To see TF-IDF scores for a selected web page, go to the “Optimization Concepts” tab.
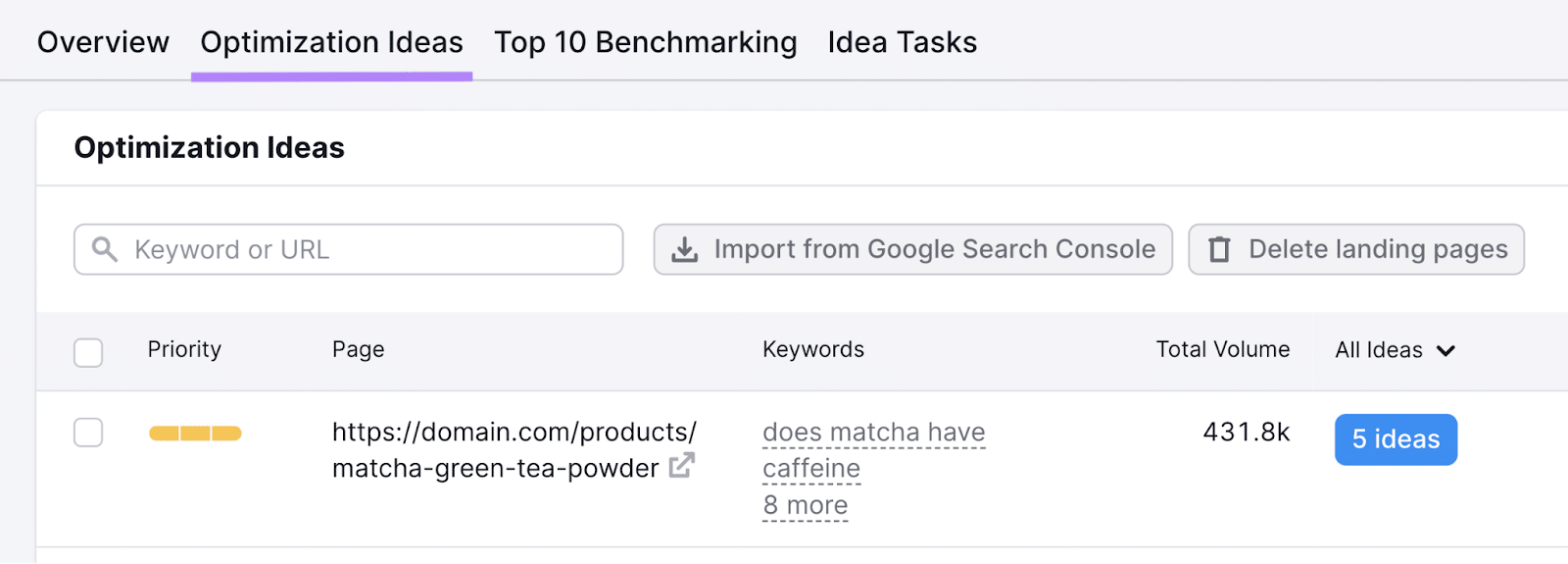
Discover your required web page within the listing, and click on the blue button exhibiting the entire variety of concepts for that web page.
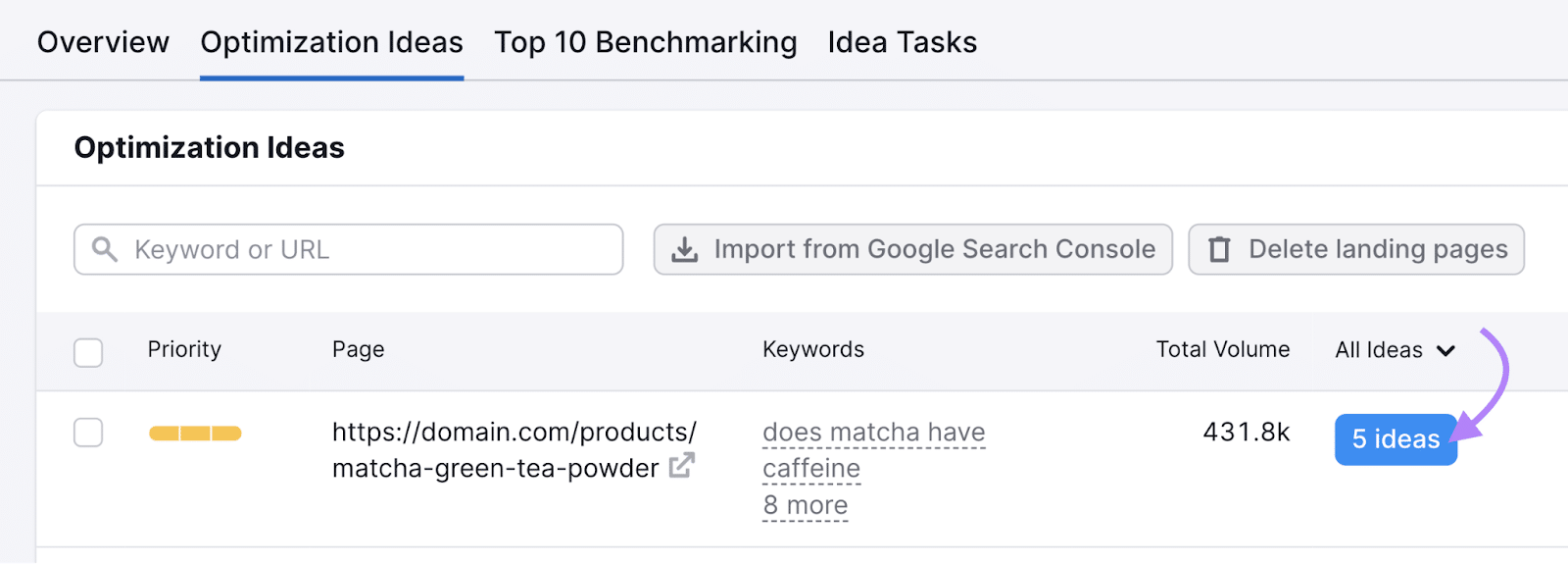
Right here, you’ll be introduced with a listing of concepts for that particular web page.
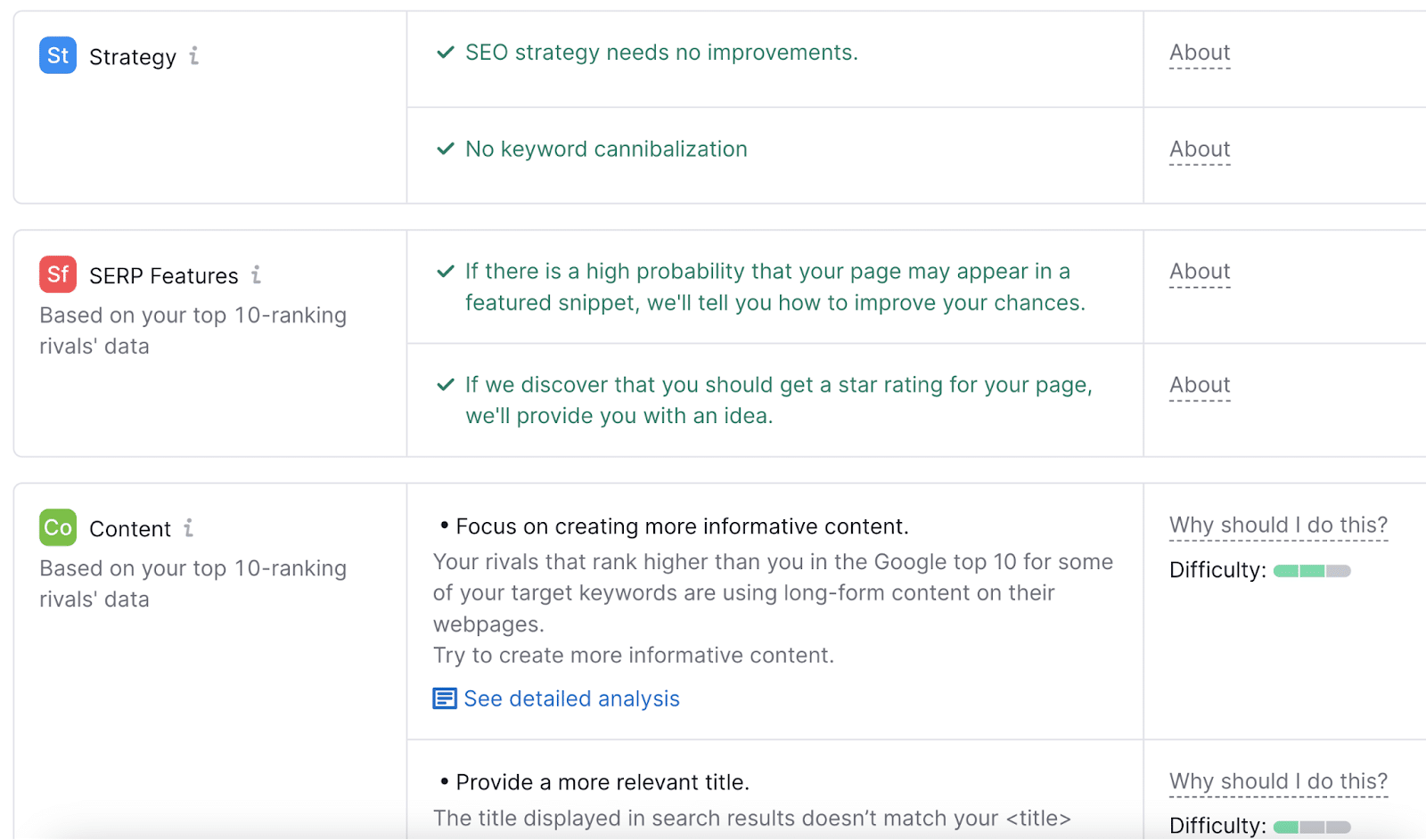
Click on on the “See detailed evaluation” hyperlink underneath any of the concepts listed within the report.
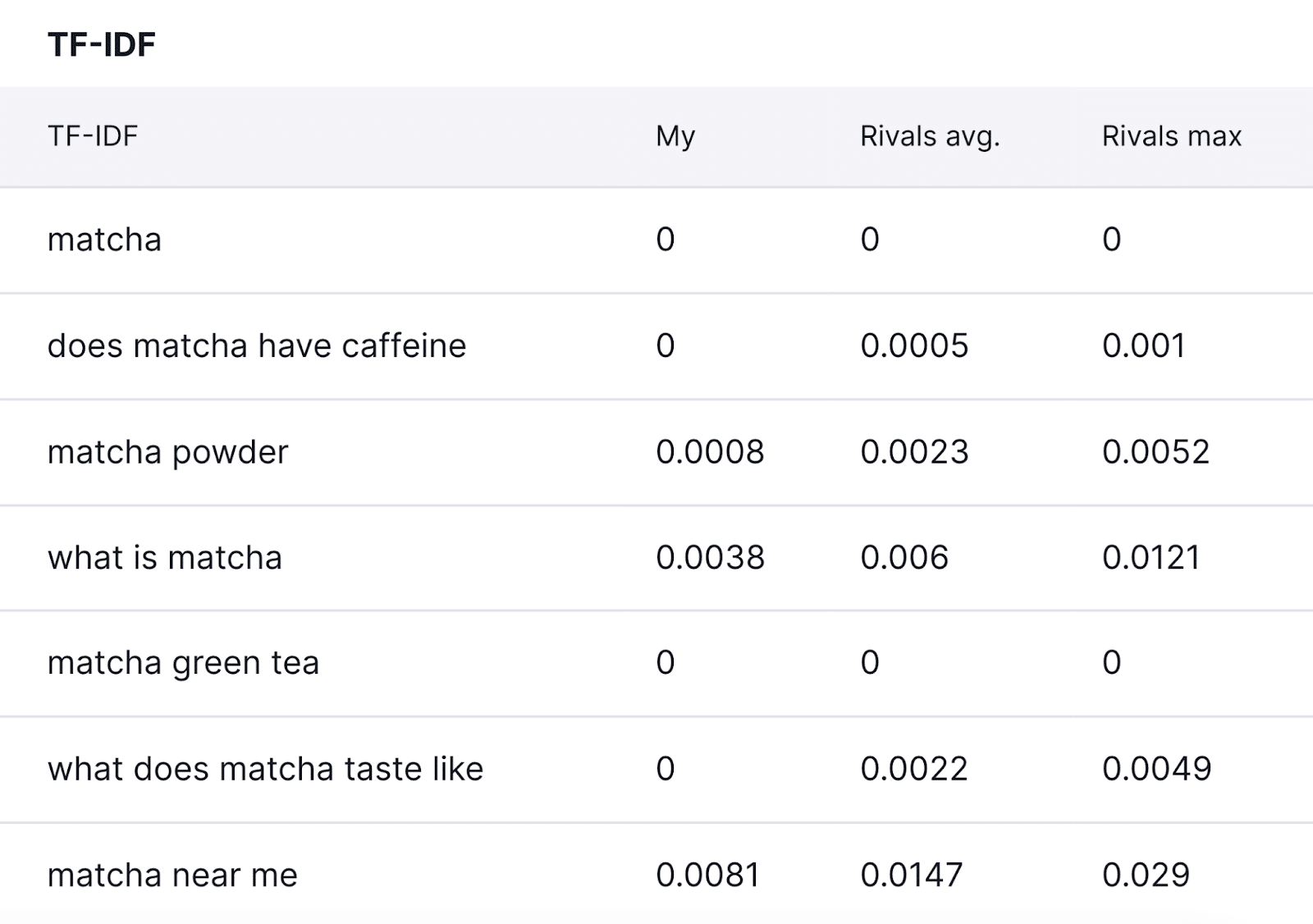
Go to the “Key phrase Utilization” tab.
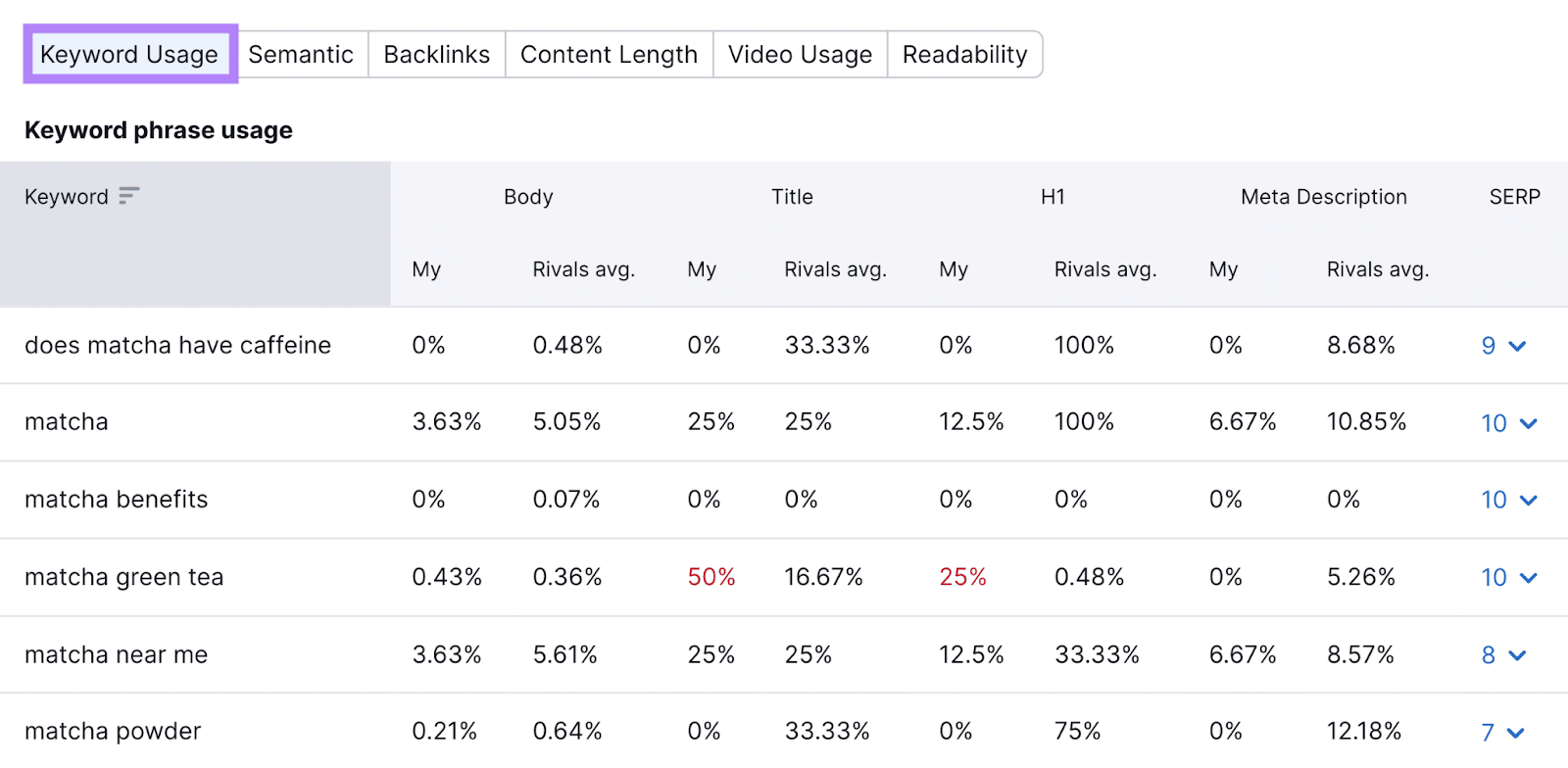
You’ll have the ability to examine TF-IDF scores within the “TF-IDF” part, as proven beneath.
Advantages of Utilizing TF-IDF
Listed here are the primary benefits of TF-IDF:
- Simple to calculate: Maybe the largest advantage of utilizing TF-IDF is that it’s pretty easy to calculate and might function a place to begin for extra superior evaluation
- Identifies necessary phrases: It could possibly assist determine necessary phrases in a doc, which may be very helpful for understanding what a doc is about
- Differentiates between frequent and uncommon phrases: Since TF-IDF seems to be at each the variety of occurrences of a time period in a single doc—in addition to the variety of occurrences of the identical time period in a group of paperwork—it helps to distinguish between frequent and uncommon phrases
- Language-independent: TF-IDF works throughout all languages and isn’t restricted by the language of a doc
- Scalable: It’s able to dealing with very large datasets containing numerous paperwork
Disadvantages of Utilizing TF-IDF
TF-IDF additionally comes with its set of limitations:
- Very uncommon phrases will be problematic: IDF scores will be misleadingly excessive for very uncommon phrases, making them appear extra necessary than they are surely
- No understanding of which means or context: TF-IDF solely measures time period frequency—it doesn’t perceive the which means behind the phrases or the context during which they’re used
- Ignores phrase order: TF-IDF doesn’t care about phrase order so it could actually’t comprehend compound nouns or phrases as single-unit phrases
- Difficulties decoding synonyms and related phrases: Since TF-IDF treats every time period independently, it could actually have difficulties recognizing synonyms and related phrases, which might result in deceptive scores
The Evolving Position of TF-IDF in AI and Machine Studying
TF-IDF has quite a few purposes for synthetic intelligence (AI) and machine studying algorithms, together with data retrieval, textual content mining, and extra.
It retains evolving alongside AI, with domain-specific TF-IDF fashions being developed for the time being. These fashions take note of the traits and nuances of particular industries they’re meant for.
Some examples embrace TF-IDF fashions aimed on the healthcare trade, that are able to analyzing scientific notes and medical information to retrieve priceless data for diagnosing and treating illnesses.
TF-IDF is now being mixed with transformer machine studying fashions (which study context by monitoring relationships between phrases).
It’s additionally being utilized together with phrase embeddings.On this method, phrases are mapped to vectors, and the relationships between them are decided primarily based on the gap in vector area.
In different phrases, these strategies enhance textual content evaluation and knowledge retrieval.
Keep on Prime of TF-IDF with Semrush
You possibly can keep acutely aware of your content material’s TF-IDF scores and examine them with these of your rivals through the use of Semrush’s On Web page search engine optimization Checker.
Other than exhibiting TF-IDF scores, the On Web page search engine optimization Checker also can make it easier to determine dozens of how to enhance your web site’s on-page search engine optimization.
And enhance your chance of rating your content material increased in search engine outcomes.
This put up was up to date in 2024. Excerpts from the unique article by Christina Sanders could stay.